Indice Show
Da qualche tempo, il termine “Machine Learning” (ML) accompagna alcune delle più innovative pubblicazioni scientifiche in ambito medico. L’utilizzo di tecniche di Machine Learning è divenuto sinonimo di accuratezza e di capacità predittive.
In particolare l’ambito oncologico fa uso del Machine Learning per prevedere il grado di aggressività di un tumore in base alle sue attuali caratteristiche. In ambito diagnostico e di predizione di outcome queste tecniche sono in grado di supportare il processo decisionale di medici e ricercatori. Scopriamo dunque il mondo del Machine Learning.
Machine learning: la tecnica degli algoritmi
Il Machine Learning è una tecnica basata su algoritmi, ossia su un insieme di procedure idonee a trovare una soluzione ad un problema secondo una sequenza finita di istruzioni. Il punto di partenza sono i dati: combinando dati secondo algoritmi, il ML è in grado di elaborare un modello idoneo a prevedere l’outcome con un ottimale margine di accuratezza.
In ambito oncologico pertanto conoscere i dati dei pazienti e creare un modello in grado di prevedere lo sviluppo di una patologia tumorale secondo tempi e gravità, può consentire la creazione di percorsi di trattamento sempre più personalizzati ed accurati.
A differenza della statistica, fondata sul concetto di inferenza (generalizzazione da campione a popolazione), il Machine Learning ha come obiettivo primario la previsione. In effetti la statistica ha lo scopo di comprendere le relazioni tra variabili e nei casi più semplici consente di prevedere l’outcome (vedi regressioni lineari o logistiche). Il Machine Learning invece mira a prevedere come le relazioni tra variabili, specialmente quelle più complesse, possano dare origine ad un certo outcome.
Learning: la parola chiave della tecnica ML
Elemento chiave del Machine Learning è proprio il “learning”. Anche qui il Machine Learning evidenza la differenza con gli strumenti di indagine di tipo statistico, fondando il proprio funzionamento sull’apprendimento. A mano a mano che i dati fluiscono dentro l’algoritmo infatti la macchina non resta a guardare, ma apprende.
Ad una prima occhiata questo processo sembra non discostarsi molto da tutti i metodi analitici comunemente usati. La modellizzazione matematica è un esempio di modelli basati su leggi. Ci si potrebbe chiedere allora: “qual è la rivoluzione del Machine Learning”? Questo singolare e apparente gioco di prestigio entra in azione proprio quando i modelli analitici sono difficili da identificare e/o da applicare.
Ti faccio un esempio. Immaginiamo di scrivere a mano i numeri da 0 a 9 su un foglio di carta ed in modo casuale. La tua scrittura sarà sicuramente differente dalla mia. Ma sia che io legga il tuo scritto sia che tu legga il mio, entrambi saremo in grado di identificare correttamente i numeri scritti sul foglio. Proviamo ora a passare uno dei due scritti su un qualsiasi computer e chiediamo alla macchina di leggere i numeri. Le probabilità che il computer possa identificare i numeri sono veramente basse. Ciò avviene in quanto il computer non ha imparato a riconoscere i numeri scritti a mano. Potrebbe farlo, ma solo se avesse potuto apprendere i numeri con la stessa metodologia con cui sono stati insegnati a noi sviluppando nel contesto una serie di processi di apprendimento.
Bisogna aggiungere che nell’esempio citato siamo in grado tu ed io di identificare i numeri perché non solo abbiamo seguito una metodologia particolare, ma abbiamo sviluppato i processi di apprendimento nella misura in cui ci siamo allenati a farlo.
La logica del machine learning
Il Machine Learning segue esattamente i processi di apprendimento come se si trattasse di una persona. Vale a dire impara a mano mano che lo si addestra. Elabora i nostri dati e apprende dagli stessi dati (training), costruisce un modello e lo applica restituendo un output. In altri termini prova a simulare il nostro metodo di apprendimento per dare risultati sempre più prossimi a quelli che un uomo con una vasta esperienza e conoscenza può dare.
Il Machine Learning fonda la propria efficacia su un semplice ragionamento: è possibile trovare un modello idoneo a prevedere l’output di un fenomeno dai dati forniti per l’addestramento. Semplice vero? Guarda lo schema della figura seguente.
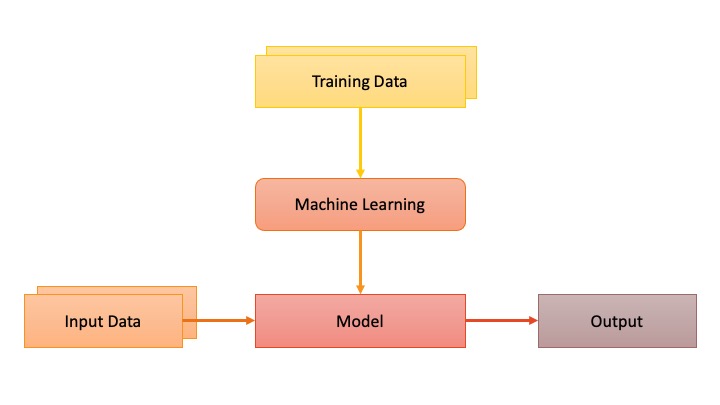
Equilibrio tra generalizzabilità e sovrastima
Nella figura sopra puoi notare due diversi percorsi che conducono al modello e all’output: il primo che prende origine dai dati di training (allenamento) ed il secondo che parte da dati distinti dai primi. Il punto focale del Machine Learning è proprio qui. Se addestrassimo un sistema fine a se stesso, dunque adoperando i dati di training e prevedendo solo per essi l’output, il sistema sarebbe inutile. Tornando all’esempio della lettura dei numeri, sarebbe come se sapessimo leggere i numeri solo quando sono scritti dalla maestra.
Ciò che ci interessa è addestrare un modello in grado di darci un output accurato quando inseriamo nuovi dati (identificare qualsiasi numero scritto a mano chiunque sia il soggetto che lo ha scritto). Questo significa generalizzare. Tanto più il modello è accurato e può generalizzare, tanto più la nostra previsione è corretta ed applicabile in vasta scala al campo di indagine.
Il rovescio della medaglia
Come sempre avviene in ambito scientifico, non esiste il modello perfetto! O almeno forse non lo abbiamo ancora scoperto! Il Machine Learning prova a fare di un computer qualcosa di similare al nostro cervello, con tuttavia tutte le limitazioni del computer. Tanto più proviamo a generalizzare, tanto più supponiamo che i dati di addestramento siano perfetti, tanto più perdiamo informazioni e dunque produciamo una sovrastima della previsione.
Il Machine Learning, confrontando diversi modelli, ha come obiettivo quello di trovare il modello ottimale idoneo a prevedere con un alto margine di accuratezza senza tuttavia incorrere in sovrastima. Tale ricerca viene eseguita mediante due approcci: la regolarizzazione, ossia un metodo numerico idoneo a costruire un modello il più semplice possibile, e la validazione, ossia un approccio che, dopo aver diviso i dati a disposizione in due gruppi (solitamente rapporto 8:2), utilizza il gruppo più ampio come dati di apprendimento e il gruppo più piccolo come strumento di valutazione e monitoraggio della performance. La validazione è l’approccio più utilizzato nelle tecniche di Machine Learning e consente, attraverso diversi modi di identificazione dei due gruppi, di poter aumentare l’accuratezza e la generalizzabilità del modello finale.
Conclusione
Il mondo della ricerca medica è da sempre alla ricerca di strategie innovative per poter supportare i ricercatori nella soluzione delle diverse patologie. Le sfide della scienza sono molteplici e le richieste di trattamenti personalizzati e di diagnosi più accurate sono alcune delle nuove frontiere che attendono la ricerca scientifica. Il Machine Learning è uno degli strumenti di intelligenza artificiale che sicuramente migliora l’ambito medico portando la ricerca scientifica in una nuova era.